
Il testo digitale è sempre un prodotto computazionale. Il codice che sottostà ad esso ne incorpora le condizioni di leggibilità, orientando il modo in cui lo recepiamo e lo consumiamo.
In questo momento il vostro cervello è alle prese con un testo, inteso come l’insieme di parole che compongono il mio scritto. Il testo, si sa, è l’unità funzionale e semantica della comunicazione linguistica. Può essere un semplice sintagma, una frase o una giustapposizione di più frasi. Sono testi tanto l’espressione «oggi piove», composta da due sole parole, quanto il contenuto-fiume della Recherche di Proust. Nel caso in esame, il testo è costituito dal post che state leggendo.
Testi orali e testi scritti
Qui ci occupiamo infatti solo dei testi scritti e di quel processo mentale che chiamiamo lettura. Naturalmente sappiamo che qualunque enunciato più o meno complesso, orale o scritto, è un testo.
Il processo della lettura è articolato e include diverse sottoattività. Tutto parte dalla capacità di riconoscere le lettere in quanto lettere (a, b, c, …), distinguendole da segni di altro tipo. Esso prevede poi il discernimento di ciascuna lettera nelle sue innumerevoli varianti allografe (la a in quanto a, distinta dalla b) e l’identificazione di insiemi coerenti di lettere che chiamiamo parole. Parlo di lettere perché il testo che state leggendo è scritto in una lingua alfabetica. In realtà dovrei parlare di grafemi, comprendendo così nel mio discorso anche le unità grafiche elementari delle lingue non alfabetiche. Il carattere 危, per esempio, non è una lettera ma un logogramma (condiviso dal cinese hanzi, dal giapponese kanji e dal coreano hanja): a differenza della lettera, esso non rappresenta solo il significante ma anche il significato. Il processo della lettura prosegue con l’associazione di ogni parola a un suono e quindi a un significato, per concludersi con il passaggio dal significato delle singole parole a quello delle frasi.
Scritture, iscrizioni, documenti
Leggere significa dunque confrontarsi con un testo scritto. Ma i testi scritti sono in realtà iscritti, nel senso che sono “eseguiti” in un qualche tipo di supporto. Assumo, per esempio, che stiate leggendo questo mio testo per come esso vi appare sullo schermo di un personal computer o di uno smartphone. Potreste anche averlo stampato. In questo caso il testo sarebbe disposto su un foglio di carta. Questo “disporsi” del testo in modo diverso, a seconda del supporto, ha ovviamente la sua rilevanza. La disposizione – su carta o schermo, desktop o mobile – condiziona il modo in cui state recependo il mio testo. Ci interessa dunque riflettere sul rapporto fra testo e disposizione (display).
Esiste un testo allo stato neutro, amodale, basico? Esiste, cioè, un grado zero della testualità? Nel gergo dell’informatica l’espressione plain text designa del materiale “leggibile” privo di qualsiasi marcatura (markup, markdown) o indicazione di layout: tipo di carattere (font), tabulazioni e indentazioni, arrotondamento degli apici, spazi unificatori, trattini morbidi, trattini lunghi, legature fra due o più caratteri (per esempio œ, &, ß) ecc. In senso lato, plain text è un testo privo di attributi: un testo, per così dire, al suo grado zero.
Il surplus del testo
I computer possono supportare diverse codifiche di carattere. Tuttavia dal 2004 è generalizzato lo standard UTF-8, che è definito dal consorzio Unicode e che integra al proprio interno il “vecchio” ASCII (American Standard Code for Information Interchange) pubblicato nel 1968.
In genere al plain text si contrappone il testo “ricco” (rich text o styled text), ovvero una rappresentazione testuale completata da informazioni quali l’identificativo della lingua, la dimensione del grafema, il suo colore, i collegamenti ipertestuali.
In formato plain text o su carta, per esempio, il testo «Ciao, mondo» corrisponde a 11 byte di informazione. Ciascuna lettera o segno di interpunzione corrisponde a un carattere. E ciascun carattere è un’unità informativa. In formato PDF, lo stesso testo ha una dimensione di 24.000 byte. Questo surplus di informazione non è indirizzato al lettore, ma al canale. I 24.000 byte di informazione non riguardano il contenuto (il «che cosa»), ma le regole di ingaggio del lettore (il «come»).
Verso una poetica del codice
Ci si domanda, appunto, se i testi che leggiamo in formato digitale siano facilmente liberabili da tale surplus, cioè se l’esperienza di una testualità totalmente neutrale sia in concreto possibile. Oppure se non si tratti di un’ipotesi utopica quanto la «mitologia del linguaggio letterario» formulata da Roland Barthes (Le Degré zéro de l’écriture, 1953; tr. it. 1960).
Il passaggio dall’ecosistema della carta a quello digitale induce in questa prospettiva a nuove riflessioni. Se la poetica «è la teoria delle scelte possibili che si offrono all’autore di un testo» (Enciclopedia Treccani), forse è necessario provare a definire una poetica dei testi sullo schermo. Un tentativo in tal senso è quello di Dennis Tenen. Il suo Plain text: the poetics of computation (Stanford University Press, Stanford CA, 2017) formula una serie di ipotesi interessanti, che vale la pena di riprendere.
In estrema sintesi Tenen sostiene tre cose: 1) quando si tratta di definire le forme della testualità, le scelte possibili per un autore e per il suo lettore sono orientate dalla tecnologia; 2) nel caso della tecnologia digitale, la struttura che orienta è il codice software, ossia ciò che si trova dietro lo schermo; 3) il testo che appare sullo schermo è dunque un’apparenza o, per meglio dire, un simulacro.
Il mezzo è il messaggio
Nel ragionamento di Tenen c’è tutta la lezione di Marshall McLuhan, secondo la quale il medium determina la nostra situazione (il famoso, quanto poco compreso «il mezzo è il messaggio» di Understanding Media: The Extensions of Man). Ma vi si coglie in qualche modo anche un’eco della sociologia dei testi di Donald Francis McKenzie, e in particolare l’idea che la forma materiale dei testi ne determini il significato.
Secondo Tenen, dunque, la tecnologia digitale incorpora una serie di strutture non sempre evidenti, le quali condizionano il modo in cui i testi sono scritti e letti. La sembianza del testo che si dispone nello schermo è un simulacro. Le parole si manifestano nel monitor, ma in realtà sono elaborate altrove, da qualche parte nella macchina. In questo senso, la bidimensionalità del testo digitale è un’illusione.
La magia dell’inchiostro elettronico
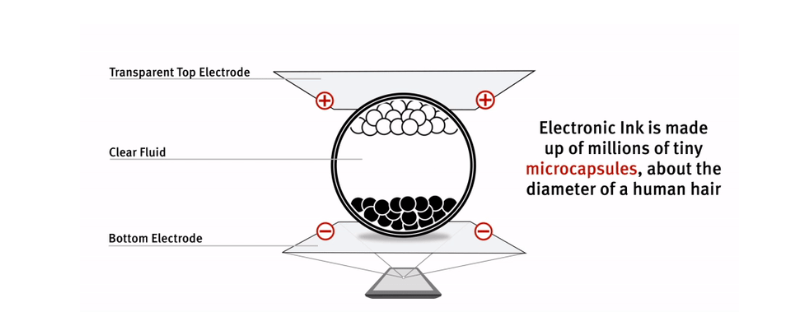
In un ereader, per esempio, è illusorio il riferimento all’inchiostro. Perché per definizione l’inchiostro è qualcosa che si fissa sul supporto scrittorio, dopo un rapido essiccamento. Al contrario, l’immagine prodotta su un EPD (electronic paper display) è volatile. Nella sua versione di base, a due pigmenti, l’inchiostro elettronico è costituito da milioni di microcapsule, ognuna delle quali ha il diametro di un capello umano. Ogni microcapsula contiene particelle bianche con carica negativa e particelle nere con carica positiva. Le une e le altre sono sospese in un fluido trasparente. Quando viene applicato un campo elettrico positivo o negativo, le particelle corrispondenti si spostano verso la parte superiore della microcapsula dove diventano visibili allo spettatore. In questo modo la superficie appare bianca o nera.
Software takes command
Il sofware assume il controllo, ci ricorda Lev Manovich (Software takes command, New York e Londra, Bloomsbury, 2013). In effetti, il software governa i meccanismi di codifica, trasmissione, immagazzinamento e decodifica dei testi nei dispositivi di lettura digitali, generando per il lettore una situazione esperienziale che dissimula la realtà profonda del dispositivo.
Pensiamo, per esempio, all’atto di cancellare una parola in un documento di Word. Ciò che appare (l’eliminazione della parola dallo schermo) non corrisponde a ciò che è (l’eliminazione della parola dalla memoria del dispositivo). Non a caso, basta agire sul comando ‘Annulla’ per ripristinare la parola apparentemente cancellata.
L’immagine del testo su un monitor a cristalli liquidi simula a propria volta la fissità del testo stampato. In realtà le lettere sullo schermo appaiono e scompaiono secondo un ciclo che si ripete con una frequenza (Hertz) pari a circa 60 volte al secondo.
La trasfigurazione del testo
Dietro la superficie visibile avviene qualcosa che solo in parte controlliamo e comprendiamo. Tenen parla di «trasfigurazione», nel senso che vi è qualcosa di incongruo nei diversi “stati” che il testo assume nel suo percorso digitale: dalla tastiera dello scrittore alla codifica elettromagnetica, dalla codifica all’iscrizione in un supporto fisico (hard disk o altro tipo di memoria), e ancora dal supporto fisico alle linee della rete telefonica mediante ulteriore decodifica e ricodifica, dalla rete a un altro dispositivo e infine dalla memoria di tale dispositivo allo schermo, affinché tale testo sia visualizzato dal lettore. Pensate alle parole che state leggendo in questo momento: ciò che appare ai vostri occhi è il punto finale di tutte queste trasformazioni.
Peraltro sappiamo che il trasferimento di un testo da un terminale all’altro può comportare cambiamenti sostanziali nel modo in cui tale testo appare. Pensiamo all’e-mail, per esempio. Quello che risulta a noi, quando formattiamo un messaggio di posta elettronica, può mostrarsi in modo diverso nel client del lettore a cui tale messaggio è destinato.
Il formato è il messaggio
Adobe ha cercato di risolvere questo problema introducendo il formato PDF. In teoria esso offre la garanzia che qualsiasi lettore veda un documento esattamente nel formato che il suo autore ha definito. Tuttavia ciò limita le possibilità di visualizzazione. Un documento PDF composto in formato A4 (210 x 297 mm), per esempio, è di difficile visualizzazione nel monitor di un dispositivo di piccole dimensioni, come un tablet o uno smartphone.
Inoltre un documento PDF presenta altre limitazioni. Per esempio non può essere arricchito con note o commenti del lettore, se non utilizzando software proprietari che comportano costi addizionali.
Insomma, parafrasando e aggiornando McLuhan si può dire che il formato (non il medium) è il messaggio. E il formato è una sovrastruttura solo in parte governata da chi scrive e da chi legge.
Senza formattazione?
Il testo che state leggendo è stato composto con Ulysses, un editor che spesso utilizzo per scrivere al computer. Ulysses permette di lavorare con un markup minimale: la formattazione viene definita inserendo semplicemente alcuni caratteri facili da ricordare. Non sono disponibili stili e formati WYSIWYG (What You See Is What You Get). Il testo è formattato automaticamente solo dopo averlo esportato in formato PDF, come pagina web o come ebook. Così ci si può concentrare meglio sulla scrittura. «Siamo convinti che il cuore del processo di scrittura sia ciò che vuoi dire e non una bella formattazione», recita il messaggio di benvenuto di Ulysses ai propri utenti.

In un certo senso, Ulysses insegue il sogno di un testo al grado zero. Ma la questione è affrontata dal punto di vista di chi scrive, non di chi legge. Una volta composto, il testo viene convertito in una serie di formati standard come solo testo o testo formattato, DOCX, HTML, ePub o PDF. La conversione avviene traducendo l’input solo testo sulla base delle definizioni del markup leggero.
Al lettore non resta che fare i conti con i formati di output e, insieme ad essi, con gli ulteriori vincoli imposti dall’infrastruttura che utilizzerà per leggere questo testo.
Decostruire le piattaforme
Il codice non incorpora infatti solo il processo di trasfigurazione descritto in precedenza. Il controllo a livello di piattaforma e di architettura dell’ecosistema digitale della lettura include anche sistemi di filtraggio (per esempio i motori di raccomandazione), di gestione dei diritti, di promozione pubblicitaria. Il codice che governa il testo incorpora leggi, vincoli, modelli di comunicazione e condizioni di lettura. Produrre un libro elettronico significa stabilire, attraverso il codice, come e dove tale libro potrà essere venduto e se esso potrà essere condiviso, commentato o modificato.
Ecco perché diventa quanto mai urgente definire una poetica computazionale. Serve – per usare le parole di Tenen – «una strategia di interpretazione capace di andare oltre la superficie del contenuto, per decostruire le piattaforme e le infrastrutture che mettono in scena la costruzione del significato» di un testo (pag. 6, traduzione mia).
Algoritmi di lettura
L’esperienza della lettura nell’ecosistema digitale contempla un certo livello di delega alla macchina da parte del soggetto. Questo – osserva Tenen – rischia di scomparire dentro la macchina, mentre la macchina assume la forma di un attore animato e intelligente: «la nostra capacità di comprendere la politica degli oggetti intelligenti dipende dalla formulazione della loro poetica, ossia del modo in cui sono fatti». (ivi, pag. 15)